
An overview of the SQL GROUP BY clause
This article briefly explains the SQL group by clause, when it should be used, and what we should consider when using it.
Side Note: All code examples in this article are made using SQL Server 2019 and Stack Overflow 2010 database.
Mục Lục
What is “Grouping” in SQL, and why is it needed?
Consider that we are analyzing the Stack overflow QA website database. This database contains several tables that store information about the website users, posted questions, answers, comments, and awarded badges.
For example, let’s take the “Posts” table. This table contains all information about different types of posts on the QA website; questions, answers, wiki, moderators’ nominations… If we are looking to count the number of each type of post, using a simple SELECT statement can return the number of rows of a single type by using the COUNT() function besides filtering the result using the WHERE clause:

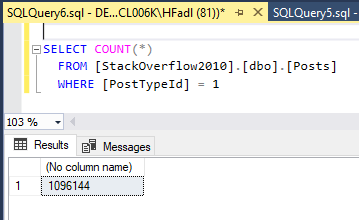
Figure 1 – Calculating the number of rows for one post’s type
If we try to add the PostTypeId column before the COUNT(*), the SQL command will not be executed and will throw the following exception to notify the user that aggregation is required to perform this operation:
Column ‘StackOverflow2010.dbo.Posts.PostTypeId’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
The SQL GROUP BY clause arranges similar data stored within one or several columns into groups, where an aggregate function is applied to produce summaries. For example, calculating the number of posts for each user.
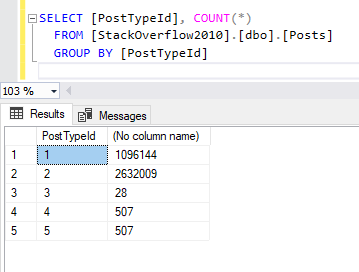
Figure 2 – Calculating the number of each type of post
SQL query execution order
Before explaining the SQL GROUP BY clause and when we should use it, we need to know how is the SQL query executed by the database engine. Once asking to execute a SQL command, the database engine parses the different parts of it in the following order:
- FROM / JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- OFFSET
GROUP BY clause
As defined in the Microsoft official documentation, a SELECT – GROUP BY command is a SELECT statement clause that divides the query result into groups of rows, usually to perform one or more aggregations on each group. The SELECT statement returns one row per group”.
The syntax of the GROUP BY clause is as follows:
1
2
3
4
5
6
7
8
9
GROUP
BY
{
column
–
expression
|
ROLLUP
(
<
group_by_expression
>
)
|
CUBE
(
<
group_by_expression
>
)
|
GROUPING
SETS
(
<
grouping_set
>
)
|
HAVING
(
<
filter
expression
>
)
}
A SQL GROUP BY clause can be used to perform aggregations over each group or even to remove duplicated rows based on the grouping expression. For example, assume that we need to extract all the distinct locations of the Stack Overflow users. We can simply add the DISTINCT keyword after the SELECT term.
1
2
3
4
SELECT
DISTINCT
[
Location
]
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Users
]
Or, we can use a SELECT – GROUP BY command to achieve the same thing:
1
2
3
4
5
SELECT
[
Location
]
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Users
]
GROUP
BY
[
Location
]
It is worth mentioning that both queries have the same execution plan.
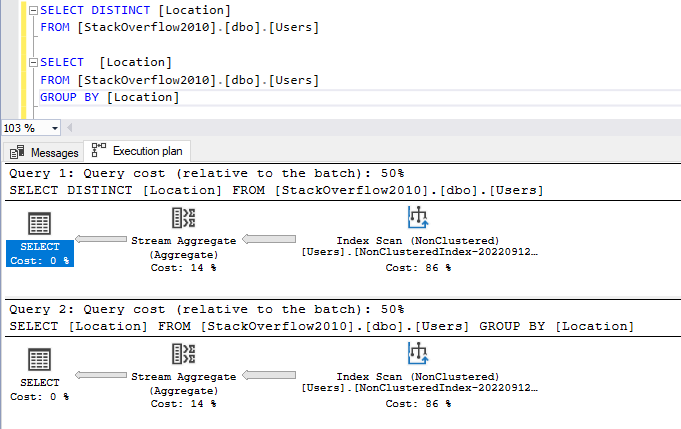
Figure 3 – Execution plans comparison
Now, we can add an aggregation function in the SELECT clause to perform it per each group.
1
2
3
4
5
SELECT
[
Location
]
,
COUNT
(
*
)
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Users
]
GROUP
BY
[
Location
]
As shown in the image below, all NULL values are considered equal and collected into a single group.
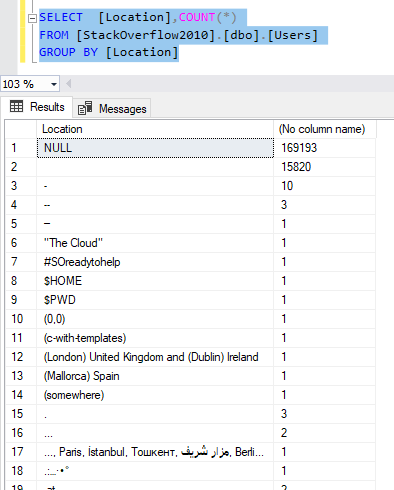
Figure 4 – Adding an aggregate function to the SELECT – GROUP BY command
Checking the command execution plan, we can see that after aggregating the data within groups, a scalar function is applied per each group.
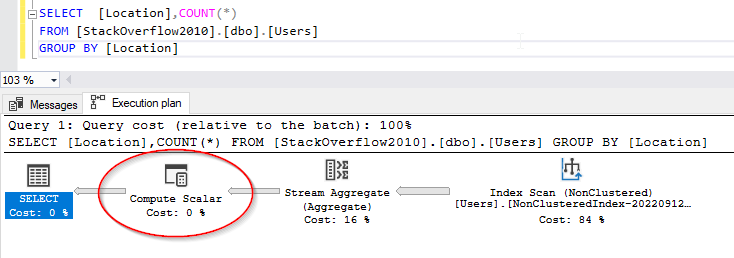
Figure 5 – Execution plan showing the aggregation function computation
GROUP BY columns
The simplest way to use the SQL GROUP BY clause is to select the columns needed for the grouping operation. All columns specified in the SELECT clause – except the aggregation functions – should be specified in the GROUP BY clause. For example, if we execute the following query:
1
2
3
4
5
SELECT
[
Id
]
,
[
Location
]
,
COUNT
(
*
)
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Users
]
GROUP
BY
[
Location
]
;
The following exception is thrown:
Column ‘StackOverflow2010.dbo.Users.Id’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
Another thing worth mentioning is that column aliases cannot be used in the SQL GROUP BY clause since it is computed before the SELECT clause by the SQL engine.
GROUP BY user-defined functions
We can also use user-defined scalar functions alongside the columns specified in the SELECT and GROUP BY clauses. For example, we created the following function to get whether a question has an answer or not:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
CREATE
FUNCTION
isSolved
(
@
PostID
INT
)
RETURNS
BIT
AS
BEGIN
DECLARE
@
Exists
BIT
SELECT
@
Exists
=
CASE
WHEN
AcceptedAnswerId
=
0
THEN
0
ELSE
1
END
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Posts
]
WHERE
[
Id
]
=
@
PostID
RETURN
@
Exists
END
The following query can be executed successfully.
1
2
3
4
5
SELECT
dbo
.
IsSolved
(
[
Id
]
)
,
COUNT
(
*
)
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Posts
]
GROUP
BY
dbo
.
IsSolved
(
[
Id
]
)
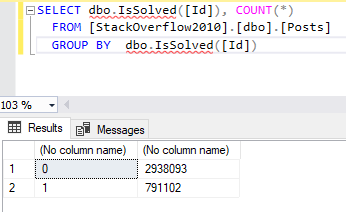
Figure 6 – Grouping by a user-defined function
GROUP BY column expressions
Another way to group the result is by using column expressions. For example, if we are looking to group the columns based on a specific computation such as a mathematical expression or a CASE WHEN expression, we can simply use it similar to a single column. For example, assume that we want to count the number of questions being solved and the number of open issues on the Stack Overflow website. Noting that the Posts table only contains a column named AccetpedAnswerId that contains the identifier of the answer.
1
2
3
4
5
SELECT
CASE
WHEN
AcceptedAnswerId
=
0
THEN
0
ELSE
1
END
,
COUNT
(
*
)
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Posts
]
GROUP
BY
CASE
WHEN
AcceptedAnswerId
=
0
THEN
0
ELSE
1
END
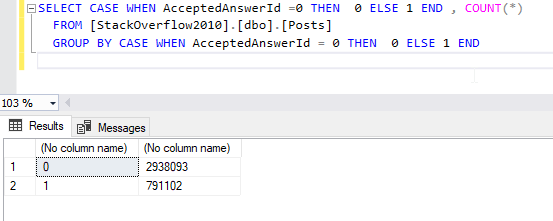
Figure 7 – Grouping by a CASE WHEN expression
GROUP BY HAVING
We cannot use the WHERE clause in this operation to filter the query result based on the group aggregated function result since the database engine executes the WHERE clause before applying the aggregate function. This is why the HAVING clause was found.
The HAVING clause can only be used with a SQL GROUP BY clause. For example, we need to get the locations mentioned in more than 1000 and less than 10000 user profiles.
1
2
3
4
5
6
7
SELECT
[
Location
]
,
COUNT
(
*
)
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
Users
]
GROUP
BY
[
Location
]
HAVING
COUNT
(
*
)
BETWEEN
1000
AND
10000
ORDER
BY
COUNT
(
*
)
DESC
;
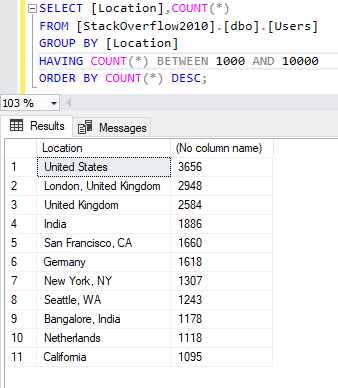
Figure 8 – Using the HAVING keyword to filter the result of a grouping operation
GROUP BY ROLLUP, CUBE, and GROUPING SETS
To explain the ROLLUP, CUBE, and GROUPING SETS options, we create a view from the Posts and Users tables with the following structure:
Posts.Id
Posts.CreationDate
Posts.PostType
Users.Location
GROUP BY ROLLUP
Let’s assume that we want to generate a report showing the number of posts in each year, quarter, and month, for each post’s type. The result should be as the following:
Creation_year
Creation_quarter
Creation_Month
PostType
PostsCount
The SQL GROUP BY ROLLUP lets us create the combinations that exist in the data in addition to rolling up within the hierarchical order we define in the ROLLUP statement. For example, let us try the following query:
1
2
3
4
5
6
7
8
SELECT
YEAR
(
[
CreationDate
]
)
as
Creation_year
,
DATEPART
(
QUarter
,
[
CreationDate
]
)
as
Creation_quarter
,
MONTH
(
[
CreationDate
]
)
as
Creation_month
,
COUNT
(
*
)
as
Number_of_posts
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
vPosts
]
GROUP
BY
ROLLUP
(
YEAR
(
[
CreationDate
]
)
,
DATEPART
(
QUarter
,
[
CreationDate
]
)
,
MONTH
(
[
CreationDate
]
)
)
As shown in the image below, the result includes three levels of aggregations:
- The number of posts per month
- The number of posts per quarter
- The number of posts per year
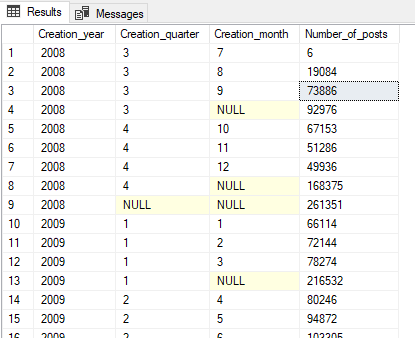
Figure 9 – Using the ROLLUP statement to apply aggregation on different hierarchical levels
GROUP BY CUBE
Now, let’s assume that we are asked to generate a report that shows the number of posts per user location, the post type, or both.
THE SQL GROUP BY CUBE statement produces every possible combination between the columns mentioned in the CUBE statement. For example, let’s try the following command:
1
2
3
4
5
6
SELECT
[
Location
]
,
[
Type
]
,
COUNT
(
*
)
as
Number_of_posts
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
vPosts
]
GROUP
BY
CUBE
(
[
Location
]
,
[
Type
]
)
As shown in the image below, the results contain three groups:
- The number of posts per location
- The number of posts per type
- The number of posts per location and type
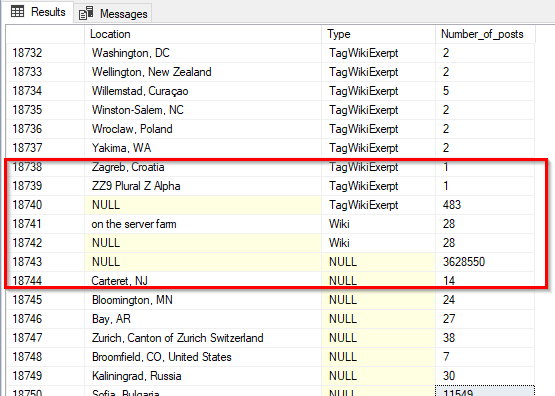
Figure 10 – Using the GROUP BY CUBE statement
GROUP BY GROUPING SETS
Sometimes we will be asked to only generate a report for only some specific combination of columns and expressions. In this case, using the CUBE or ROLLUP may be inefficient and time-consuming.
For this reason, we can use the GROUPING SETS statement, where we should define each combination explicitly. For example, we only want to generate a report showing the number of posts per location, per type, and the total number of posts.
1
2
3
4
5
6
7
8
9
10
SELECT
[
Location
]
,
[
Type
]
,
COUNT
(
*
)
as
Number_of_posts
FROM
[
StackOverflow2010
]
.
[
dbo
]
.
[
vPosts
]
GROUP
BY
GROUPING
SETS
(
(
)
,
— Total number of posts
(
[
Location
]
)
,
(
[
Type
]
)
)
As shown in the image below, the first five rows show the number of posts for each type, the 6th row shows the total number of posts, and the rest shows the number of posts per location.
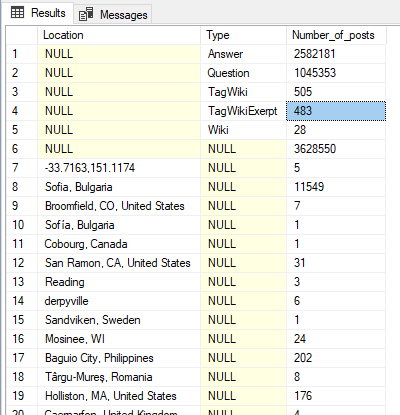
Figure 11 – using GROUPING SETS statement
Summary
This article briefly explained the SQL GROUP BY clause and how to use it to perform aggregate functions on the data. We also demonstrated the options available, such as grouping over a set of columns, expressions, and user-defined functions. In addition, we explained how to use the HAVING keyword for filtering and the ROLLUP, CUBE, and GROUPING SETS options for reporting purposes.
To learn more about the SQL GROUP BY function, you can refer to the following articles previously published on SQL Shack:





