
The Apple iPhone 6s and iPhone 6s Plus Review
A9’s CPU: Twister
Taking a starring role in A9 is Twister, the latest generation ARMv8 AArch64 CPU core out of Apple. With Cyclone Apple made a clear leap to the front of the ARM CPU development pack, and since then they haven’t looked back. Still, in the next year they will be facing ARM’s own Cortex-A72 design along with Qualcomm’s own Kryo. As a result Apple needs to progress on the CPU performance front if only to maintain their lead over other ARM vendors.
For the launch of the Apple A8 last year, Apple put together the Typhoon CPU core. Even though Typhoon was for a non-S iPhone, Apple still managed to integrate some basic architectural optimizations that put it ahead of Cyclone. This was important because Typhoon would only reach 1.4GHz in phones – likely a trade-off imposed by the temperamental 20nm process – and as a result Apple needed their CPU architecture to carry the day.
However with the iPhone 6s, all of the stars are coming into alignment for Apple. On the one hand as this is an iPhone S release, even more is expected of them on the architectural side of matters. On the other hand between the power benefits of the FinFET processes and Twister’s place in Apple’s seeming 2-year cycle, Apple will get to run up the score twice: once with clockspeed and once with a more substantial architecture improvement.

In fact on the clockspeed front this is the biggest jump in CPU frequencies since Swift in the A6, where Apple went from an 800MHz ARM Cortex-A9 to the aforementioned custom Swift design at 1.3GHz. As a result Apple immediately gets to capitalize on a 450MHz (32.1%) clockspeed bump for Twister in the A9 versus the Typhoon-powered A8. That large of a clockspeed bump alone would be enough to give Apple a sizable performance boost, especially as competing designs are already at 2GHz+ and are unlikely to shoot much higher due to power concerns.
Apple has always played it conservative with clockspeeds in their CPU designs – favoring wide CPUs that don’t need to (or don’t like to) clock higher – so an increase like this is a notable event given the power costs that traditionally come with higher clockspeeds. Based on the underlying manufacturing technology this looks like Apple is cashing in their FinFET dividend, taking advantage of the reduction in operating voltages in order to ratchet up the CPU frequency. This makes a great deal of sense for Apple (architectural improvements only get harder), but at the same time given that Apple is reaching the far edge of the performance curve I suspect this may be the last time we see a 25%+ clockspeed increase in a single generation with an Apple SoC.
As for Twister’s architecture, there’s a story here as well. Relative to the Cyclone-to-Typhoon transition, Typhoon-to-Twister is a larger architectural upgrade for Apple as we’ll see. At the same time however it’s not on the level of Swift-to-Cyclone, nor would we expect it to be. Apple’s architecture, for lack of a better word, should be “stable” for the moment, which means Apple has plenty of room to optimize their designs without flipping the table and starting over.
Unfortunately I can tell you straight up that we’re only scratching the surface on the architectural side. Apple really doesn’t like talking about CPU architecture, and every time we poke at an Apple SoC they clamp down just a bit harder. At the end of the day Apple can’t hide everything about the SoC, but a Cyclone-like disclosure is likely not going to happen with Twister.
So with that out of the way, let’s start with a low-level look at Twister, and some of the attributes of the CPU design.
Apple Custom CPU Core Comparison
Apple A8
Apple A9
CPU Codename
Typhoon
Twister
ARM ISA
ARMv8-A (32/64-bit)
ARMv8-A (32/64-bit)
Issue Width
6 micro-ops
6 micro-ops
Reorder Buffer Size
192 micro-ops
192 micro-ops
Branch Mispredict Penalty
16 (14 – 19)
9
Integer ALUs
4
4
Shifter ALUs
2
4
Load/Store Units
2
2
Addition (FP32) Latency
4 cycles
3 cycles
Multiplication (FP32) Latency
5 cycles
4 cycles
Addition (INT) Latency
1 cycle
1 cycle
Multiplication (INT) Latency
3 cycles
3 cycles
Branch Units
2
2
Indirect Branch Units
1
1
FP/NEON ALUs
3 (3 Add or 2 Mult)
3 (3 Add or 3 Mult)
L1 Cache
64KB I$ + 64KB D$
64KB I$ + 64KB D$
L2 Cache
1MB
3MB
L3 Cache
4MB
8MB 4MB
In terms of execution width and reorder depth, we haven’t found anything to indicate that Twister is wider or deeper than Typoon, so the issue-width appears to still be 6 micro-ops while the out-of-order-execution reorder buffer remains at 192 micro-ops. A 6-wide design was and remains atypically large for a 64-bit ARMv8 design, and this is one of those “stable” aspects that is likely not to change anytime soon. As for the OoO reorder depth, contemporary experience is that deeper OoO reorder windows eat more power, in which case this is something that Apple may want to hold off on until they can’t pick up performance gains elsewhere.
What’s far more interesting is the branch prediction latency. While we don’t have Apple’s official numbers – that being where 16 and the 14-to-19 range originate from for Cyclone – our testing indicates that branch misprediction penalties are way down. The average misprediction penalty is just 9 cycles, significantly lower than the official or average misprediction penalties for Cyclone/Typhoon. Without more architectural information I don’t want to read into this too much – shorter penalties could imply a shorter pipeline – however at a minimum this means that Apple’s performance just got a lot better whenever they do miss a branch.
Meanwhile the number of FP/NEON units, Integer units, and Load/Store units is unchanged from Typhoon, but the performance of those ALUs has shifted, both for Integer and FP workloads. Twister still retires up to 3 FP32 additions per cycle, but the latency has dropped from 4 cycles to 3 cycles, which is all the more remarkable with Twister’s clockspeed boost (this brings the real-time latency from ~2.9ns to ~1.6ns). In fact FP32 multiplication latency is down as well, from 5 cycles to 4 cycles. Coupled with this, FP32 multiplication throughput on Twister is increased, indicating that it is now capable of retiring 3 FP32 mults per cycle, as opposed to 2 under Twister. As a result Twister should show some rather significant improvements in floating-point heavy workloads.
On the Integer side of matters on the other hand, things haven’t changed nearly as much. Integer throughput and latency remain unchanged for addition and multiplication. However the shifters, which we rarely talk about, have been improved. All 4 integer pipelines can now also do shifts, up from 2 on Typhoon. Shifters are an important type of ALU resource, however unlike basic arthimetic operations it’s a bit less obvious when it’s in use, so while there will be performance benefits from this change it’s not as easy to predict where we’ll see them.
Finally, looking at Twister’s caches, while the L1 cache sizes remain untouched from Typhoon, Apple has managed to pack in larger caches for both the L2 and L3. The size of the L2 cache in particular has really ballooned, going from 1MB on Typhoon to 3MB on Twister. The benefit of growing this cache is that Apple now can store much more in the way of data and instructions closer to the Twister cores before going to L3, but the tradeoff is that cache access times typically go up a bit as it takes longer to find something in the cache.
The L3 cache meanwhile doesn’t see quite the same increase in size, and it is still 4MB in size. However now it is a victim cache rather than an inclusive cache (more info here). but it is now 8MB instead of 4MB, a solid doubling. As a reminder, this cache is shared between the CPU and GPU (among other blocks), so increasing this cache benefits both major parts of the SoC. However it’s also worth mentioning that as Apple is using an inclusive style cache here – where all cache data is replicated at the lower levels to allow for quick eviction at the upper levels – then Apple would have needed to increase the L3 cache size by 2MB in the first place just to offset the larger L2 cache. So the “effective” increase in the L3 cache size won’t be quite as great. Otherwise I’m a bit surprised that Apple has been able to pack in what amounts to 6MB more of SRAM on to A9 versus A8 despite the lack of a full manufacturing node’s increase in transistor density.
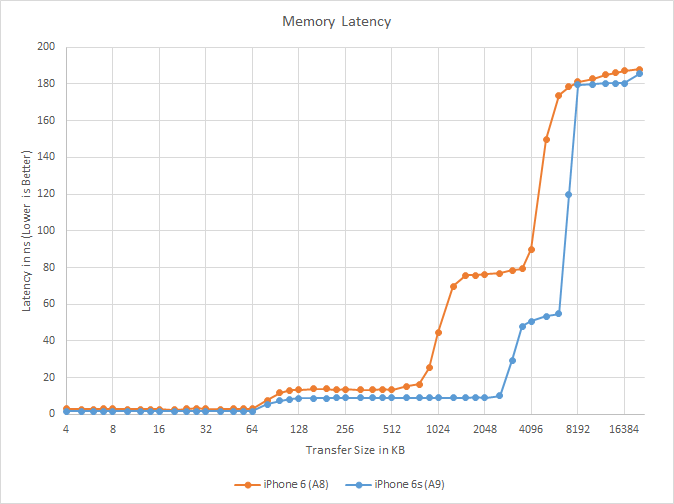
Looking at a plot of latency versus transfer size, it’s interesting to note that A9 once again improves on Apple’s cache latency. Even with the clockspeed increase Apple has not had to back off on cache access times, and as a result real-time cache latency is notably decreased versus A8 with both the L2 and L3 caches. At both levels we’re looking at cache access times 30-40% shorter than they were at A8 when hitting the respective cache, and of course A9 is far faster at the 1-3MB range where things can stay in A9’s L2 as opposed to going to A8’s L3.
Otherwise the boundary between the L3 cache and DRAM is a bit foggier than usual. We see latencies jump more rapidly at 8MB than we did on A8 at 4MB, but as the only other practical cache size is 6MB (where access times are still at L3 cache norms) then the most likely explanation is that cache pressure is a bit higher on the A9 versus the A8, making it harder for our test to grab all 8MB of L3 for itself.
Beyond that is the LPDDR4 DRAM, a first for an Apple SoC. The successor to LPDDR3, LPDDR4 is designed to further reduce the DRAM operating voltage from 1.2v to 1.1v while increasing the total bandwidth available. Do note however that the internal frequency of LPDDR4 isn’t changed versus LPDDR3, and as a result LPDDR4 latency will be similar (if not a bit worse) than LPDDR3 at the same internal frequency.
For A9 Apple is using 2GB of LPDDR4-3200, which compared to the LPDDR3-1600 used in Apple’s A8 immediately doubles their effective bandwidth. The real-world memory bandwidth increase won’t be quite that high – in part due to the fact that memory latencies haven’t really changed – but LPDDR4 still delivers a true generational increase in memory bandwidth that today’s bandwidth-starved SoCs have badly needed.
Geekbench 3 Memory Bandwidth Comparison (1 thread)
Stream Copy
Stream Scale
Stream Add
Stream Triad
Apple A9 1.85GHz
13.9 GB/s
9.41 GB/s
10.4 GB/s
10.4 GB/s
Apple A8 1.4GHz
9.08 GB/s
5.37 GB/s
5.76 GB/s
5.78 GB/s
A9 Advantage
53%
75%
81%
80%
Taking a quick look at GeekBench 3’s synthetic memory benchmark, we immediately see some sizable increases across all 4 sub-tests. Overall the increase in measured bandwidth is between 53% and 81%, with the blended Triad sub-test giving us 80%. Ultimately this test involves large sequential memory accesses – the kind of operations best suited for LPDDR4 – so CPU performance increases from LPDDR4 likely won’t be nearly as great (especially if the caches are doing their job). On the other hand those are exactly the kind of operations that GPUs are known for, so there is clearly plenty of new headroom to feed the beast that is A9’s GPU.
Moving on, now that we’ve seen what Twister and A9 are at like at a low-level, let’s see what this does for our collection of high-level benchmarks.
For our first high level benchmark we turn to SPECint2000. Developed by the Standard Performance Evaluation Corporation, SPECint2000 is the integer component of their larger SPEC CPU2000 benchmark. Designed around the turn of the century, officially SPEC CPU2000 has been retired for PC processors, but with mobile processors roughly a decade behind their PC counterparts in performance, SPEC CPU2000 is currently a very good fit for the capabilities of Typhoon and Twister. And as a brief aside, for those of you wondering about SPEC CPU2006, one of the 64-bit tests still doesn’t fit in the approximately 1.8GB of usable user-space RAM on the A9; so while we can use parts of 2006, it will be one final increase in memory before we can use the complete set.
Anyhow, SPECint2000 is composed of 12 benchmarks which are then used to compute a final peak score. Though in our case we’re more interested in the individual results.
SPECint2000 – Estimated Scores
A9
A8
% Advantage
% Architecture Advantage
164.gzip
1191
842
41%
9%
175.vpr
2017
1228
64%
32%
176.gcc
3148
1810
74%
42%
181.mcf
3124
1420
120%
88%
186.crafty
3411
2021
69%
37%
197.parser
1892
1129
68%
35%
252.eon
3926
1933
103%
71%
253.perlbmk
2768
1666
66%
34%
254.gap
2857
1821
57%
25%
255.vortex
3177
1716
85%
53%
256.bzip2
1944
1234
58%
25%
300.twolf
2020
1633
24%
-8%
Across the board, SPEC scores are way, way up. Even the smallest gain with twolf is at 24%, while at the top-end is mcf with a whopping 120% performance gain. Otherwise in the middle the average gain is closer to 60%.
Meanwhile I also took the liberty of recomputing the performance advantage after factoring out the A9’s 450MHz (31%) clockspeed advantage, which gives us something much closer to a pure architectural look at performance. In that case other than a theoretical regression on twolf – its performance gain was less than the clockspeed advantage to begin with – the average performance gain is still around 30%. To frame that for comparison, the average gain from A7 to A8, including the 100Mhz clockspeed bump, was still less than that at around 20%. So even without a clockspeed increase A9 already shows significant performance improvements from architectural and cache changes, and this only gets much better with the clockspeed increase.
As for the individual scores, it’s worth nothing that with Typhoon/A8, branch-heavy tests didn’t see too much of an uplift, which is not the case here and likely owing to the reduced penalty on mispredictions. At the low-end of the scale twolf and gzip show the fewest gains, and both of which are bound by the fact that the most basic execution resources (e.g. load/store and integer addition) haven’t seen significant architecture improvements. Otherwise at the other end of the spectrum is mcf, which contains a large dataset and is likely a beneficiary of the larger caches and the much faster LPDDR4 memory.
Our other set of comparison benchmarks comes from Geekbench 3. Unlike SPECint2000, Geekbench 3 is a mix of integer and floating point workloads, so it will give us a second set of eyes on the integer results along with a take on floating point improvements.
Geekbench 3 – Integer Performance
A9
A8
% Advantage
% Architecture Advantage
AES ST
1044.4 MB/s
992.2 MB/s
5%
-27%
AES MT
2.29 GB/s
1.93 GB/s
19%
-13%
Twofish ST
100.1 MB/s
58.8 MB/s
70%
38%
Twofish MT
191.5 MB/s
116.8 MB/s
64%
32%
SHA1 ST
872.1 MB/s
495.1 MB/s
76%
44%
SHA1 MT
1.64 GB/s
0.95 GB/s
73%
40%
SHA2 ST
170.1 MB/s
109.9 MB/s
55%
23%
SHA2 MT
330.7 MB/
219.4 MB/
51%
19%
BZip2Comp ST
7.15 MB/s
5.24 MB/s
36%
4%
BZip2Comp MT
14.1 MB/s
10.3 MB/s
37%
5%
Bzip2Decomp ST
11.8 MB/s
8.4 MB/
40%
8%
Bzip2Decomp MT
22.5 MB/s
16.5 MB/s
36%
4%
JPG Comp ST
27.4 MP/s
19 MP/s
44%
12%
JPG Comp MT
54.4 MP/s
37.6 MP/s
45%
13%
JPG Decomp ST
73.1 MP/s
45.9 MP/s
59%
27%
JPG Decomp MT
141.0 MP/s
89.3 MP/s
58%
26%
PNG Comp ST
1.65 MP/s
1.26 MP/s
31%
-1%
PNG Comp MT
3.23 MP/s
2.51 MP/s
29%
-3%
PNG Decomp ST
24.8 MP/s
17.4 MP/s
43%
10%
PNG Decomp MT
46.5 MPs
34.3 MPs
36%
3%
Sobel ST
113.7 MP/s
71.7 MP/s
59%
26%
Sobel MT
216.6 MP/s
137.1 MP/s
58%
26%
Lua ST
2.64 MB/s
1.64 MB/s
61%
29%
Lua MT
4.95 MB/s
3.22 MB/s
54%
22%
Dijkstra ST
8.46 Mpairs/s
5.57 Mpairs/s
52%
20%
Dijkstra MT
15.6 Mpairs/s
9.43 Mpairs/s
65%
33%
Compared to SPEC, Geekbench’s sub-tests are all over the place, especially once we factor out the clockspeed increase. CPU AES performance on A9 surprisingly sees a minimal improvement over A8 even with the clockspeed increase. Otherwise we see a couple of other tests where the performance gains were limited to the clockspeed increase, and other tests still where performance significantly improves even at an architectural level. This is a good reminder that in the real world not all applications will benefit from A9/Twister to the same degree as the “best” applications have.
Geekbench 3 – Floating Point Performance
A9
A8
% Advantage
% Architecture Advantage
BlackScholes ST
11.9 Mnodes/s
7.85 Mnodes/s
52%
19%
BlackScholes MT
23.3 Mnodes/s
15.5 Mnodes/s
50%
18%
Mandelbrot ST
1.83 GFLOPS
1.18 GFLOPS
55%
23%
Mandelbrot MT
3.56 GFLOPS
2.34 GFLOPS
52%
20%
Sharpen Filter ST
1.69 MFLOPS
0.98 GFLOPS
72%
40%
Sharpen Filter MT
3.32 MFLOPS
1.94 MFLOPS
71%
39%
Blur Filter ST
2.22 GFLOPS
1.41 GFLOPS
57%
25%
Blur Filter MT
4.33 GFLOPS
2.78 GFLOPS
56%
24%
SGEMM ST
5.64 GFLOPS
3.83 GFLOPS
47%
15%
SGEMM MT
10.8 GFLOPS
7.48 GFLOPS
44%
12%
DGEMM ST
2.76 GFLOPS
1.87 GFLOPS
48%
15%
DGEMM MT
5.24 GFLOPS
3.61 GFLOPS
45%
13%
SFFT ST
2.83 GFLOPS
1.77 GFLOPS
60%
28%
SFFT MT
5.68 GFLOPS
3.47 GFLOPS
64%
32%
DFFT ST
2.64 GFLOPS
1.68 GFLOPS
57%
25%
DFFT MT
4.98 GFLOPS
3.29 GFLOPS
51%
19%
N-Body ST
1150 Kpairs/s
735.8 Kpairs/s
56%
24%
N-Body MT
2.27 Mpairs/s
1.46 Mpairs/s
55%
23%
Ray Trace ST
4.16 MP/s
2.76 MP/s
51%
19%
Ray Trace MT
8.15 MP/s
5.45 MP/s
50%
17%
Floating point performance improvements on Geekbench on the other hand are far more consistent. Everything is positive and in the double-digits even after factoring out the clockspeed increase, and with it nothing is less than 44% faster. The architectural improvements to FP32 performance we discussed earlier – lower addition/multiplication latency and the ability to fill all 3 NEON pipes with multiplication operations – give Twister a solid foundation for improved floating point performance.
Wrapping things up, we’ll see the full impact of Twister and Apple’s shift to LPDDR4 in our full look at system performance. But in a nutshell A9 and Twister are a very potent update to Apple’s CPU performance, delivering significant performance increases from both architectural improvements and from clockspeed improvements. As a result the performance gains for A9 relative to A8 are very large, and although Twister isn’t Cyclone, Apple does at times come surprisingly close to the kind of leap ahead they made two years ago. A8 and Typhoon already set a high bar for the industry, but A9 and Twister will make chasing Apple all the harder.
At this point we also have to start looking at not only who is chasing Apple, but who Apple is chasing. With yet another round of architectural improvements and a clockspeed approaching 2GHz, comparing Apple’s CPU designs to Intel’s is less rhetorical than ever before. By the time we get to iPad Pro and can start comparing tablets to tablets, we may need to have a discussion about how Twister and Skylake compare.





