
Group by Multiple Columns in SQL – Scaler Topics
Mục Lục
Overview
To arrange identical data into groups, we use SQL group by clause. The SQL group by single column clause places all the records having the same value of only a particular column into one group. The group by multiple columns technique retrieves grouped column values from one or more database tables by considering more than one column as grouping criteria.
Scope
The article contains topics such as
- Group By One Column using aggregation functions.
- Group By Multiple Columns, Usage of Group By Multiple Columns.
Each of the topics is explained clearly with diagrams and examples wherever necessary.
Group By One Column
To arrange similar (identical) data into groups, we use SQL GROUP BY clause. The SQL GROUP BY clause is used along with some aggregate functions to group columns that have the same values in different rows. We generally use the GROUP BY clause with the SELECT statement, WHERE clause, and ORDER BY clauses.
The group by single column places all the records (rows) having the same value of only a particular column into one group.
Syntax
SELECT
column_1, column_2, ..., column_n
FROM
table
WHERE
condition
GROUP
BY
column_1, column_2, ..., column_n;
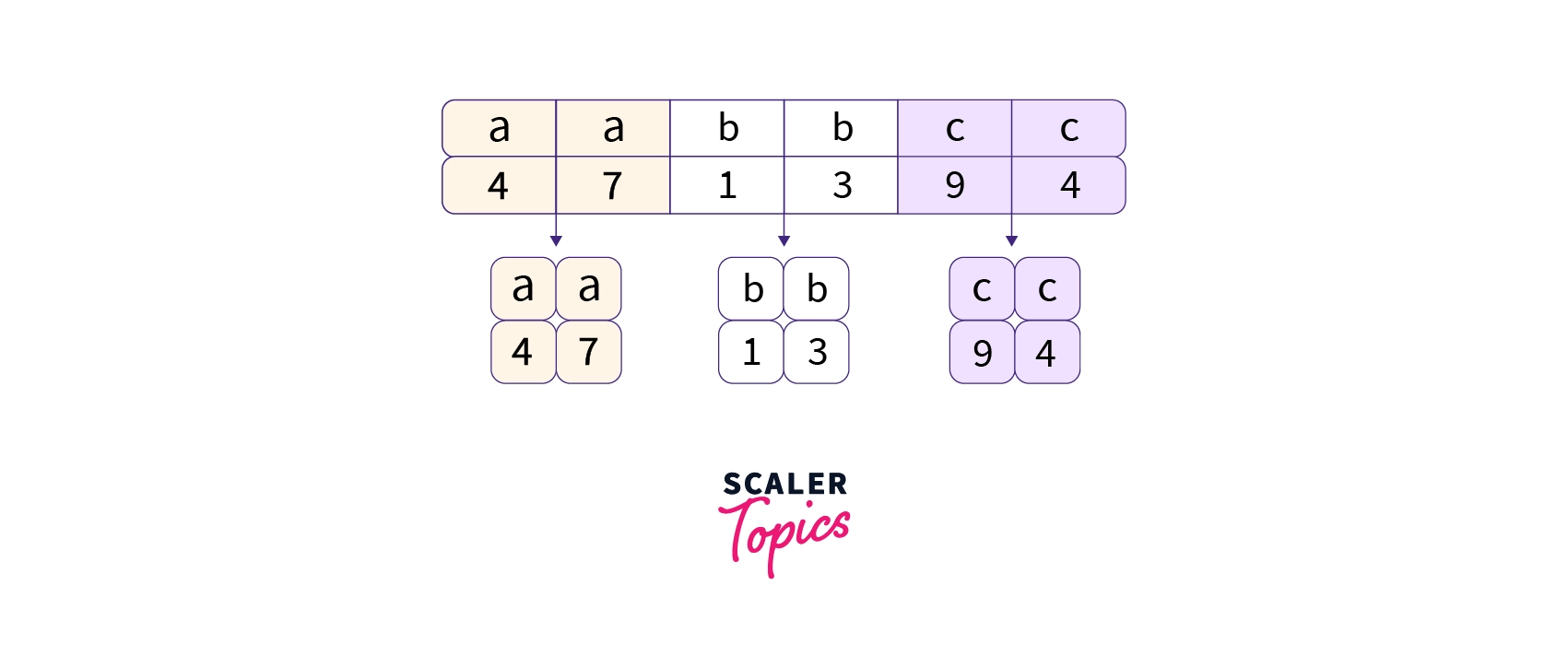
Refer to the image below to visualize grouping.
In the image above, we have grouped together similar data.
Example
Suppose we are working on a company’s database. We have two tables, namely employee and department. The employee table has three columns, namely employee_ID, salary, and department_ID. The department table has two columns, namely department_ID and department_name. Let us try to group the employees present in the employee table based on their department_ID.
employee table:
employee_IDsalarydepartment_ID10024000110117000110310000110490002105110002106160003
department table:
department_IDdepartment_name1Accounts1Marketing2IT
Query:
SELECT
SUM
(salary), department_ID
FROM
employee
GROUP
BY
department_ID;
Output:
salarydepartment_ID510001200002160003
Group by Multiple Columns
The group by multiple columns technique retrieves grouped column values from one or more database tables by considering more than one column as grouping criteria. We use SQL queries to group multiple columns of the database.
The group by multiple columns is used to club together various records with similar (or the same) values for the specified columns. Whenever we perform group by multiple columns (grouping defined on multiple columns), then all the values of those columns should be the same as that of other columns to consider them for grouping into a single record.
We use the GROUP BY clause to implement group by multiple columns.
The syntax of the GROUP BY clause is quite simple.
SyntaxSELECT
column_1, column_2,..., column_n
FROM
table
WHERE
condition
GROUP
BY
column_1_criteria, column_2_criteria,..., column_n_criteria;
In the syntax above, we first provide the names of the columns (column_1, column_2,…, column_n) of the table from which we want to retrieve the results. After the columns, we provide the targeted table name (the table from where the result is to be fetched). At last, we can provide some conditions on certain columns using the WHERE clause.
We can specify criteria on single and multiple columns (like column_1_criteria, column_2_criteria,…, column_n_criteria). We can also provide expressions as the grouping criteria.
Usage of Group By Multiple Columns
Let us discuss some of the usage and benefits of using group by multiple-column technique:
- We can use the group by multiple-column technique to
group multiple records into a single record. - All the records with the same values for the respective columns mentioned in the grouping criteria can be grouped as a single column using the group by multiple-column technique.
- The group by multiple columns is used to get summarized data from a database’s table(s).
- The group by multiple columns is often used to generate queries for reports.
Examples
Now let us take some examples of groups by multiple columns to understand the topic better.
Group by Two Columns and Find Average
Suppose we are working on a company’s database. We have two tables, namely employee and department. The employee table has three columns, namely employee_ID, salary, department_id. The department table has two columns, namely department_id and department_name. Let us try to find the average salary of employees in each department.
employee table:
employee_IDsalarydepartment_ID10024000110117000110310000110490002105110002106160003
department table:
department_IDdepartment_name1Accounts1Marketing2IT
Query:
SELECT
e.department_ID, department_name,
ROUND(
AVG
(salary),
2
) average_salary
FROM
employees e
INNER
JOIN
departments d
ON
d.department_ID
=
e.department_ID
GROUP
BY
e.department_ID;
Output:
department_IDdepartment_nameaverage_salary1Accounts170002Marketing100003IT16000
In the above query, we have joined the department and employee table and selected the department id, department name, and average salary. The average salary is accounted for by grouping employees based on their department.
Group by Two Columns and Find Multiple Stats
We have seen a grouping of employees by one column. Let us now learn how to group by multiple columns.
Let us consider the same department and employee table. The employee table has four columns, namely employee_ID, salary, department_id, and job_id. The department table has two columns, namely department_id and department_name. We have another table named job, which stores the job_id and job name.
Let us try to group by employee id and employee id.
employee table:
employee_IDsalarydepartment_IDjob_id10024000111011700011103100001110490002310511000231061600032
department table:
department_IDdepartment_name1Accounts2IT3Marketing
job table:
job_IDjob_title1Accountant2Manager3HR
Query:
SELECT
e.department_id, d.department_name, e.job_id,
COUNT
(e.employee_ID)
FROM
employees e
INNER
JOIN
departments d
ON
d.department_ID
=
e.department_ID
INNER
JOIN
jobs j
ON
j.job_ID
=
e.job_ID
GROUP
BY
e.department_ID , e.job_ID;
Output:
department_IDdepartment_namejob_IDCOUNT(e.employee_ID)1Accounts132IT323Marketing21
The output (as above) is generated using the join operation of the three tables. After the join operation, the GROUP BY condition is added. We have also added the count aggregate function on the employee ID column.
Conclusion
- To arrange similar (identical) data into groups, we use SQL group by clause. The
GROUP BY
clause is used along with some aggregate functions to group columns with the same values in different rows.
- The group by multiple columns technique retrieves grouped column values from one or more database tables by considering more than one column as grouping criteria.
- All the records with the same values for the respective columns mentioned in the grouping criteria can be grouped as a single column using the group by multiple-column technique.
- The group by multiple columns is used to get summarized data from a database’s table(s). The group by multiple columns is often used to generate queries for reports.





